안녕하세요 와우멍입니다.
오늘은 시험장에서 쓸만한 팁을 정리하면서, 중간 정리를 한 번 해보겠습니다.
빅데이터분석기사 실기 꿀팁

내가 쓰려는 패키지 이름이 잘 기억 안날 경우 dir( )
dir( ) 함수를 통해 사용하려는 모듈 내에 있는 패키지들을 확인할 수 있음.
- 아래 그림처럼 loop를 돌려서 함수 이름 앞에 언더바(_)가 붙는 애들을 제거해주면 리스트를 얻을 수 있습니다.
|
1
2
3
4
5
|
import sklearn.preprocessing
test = dir(sklearn.preprocessing)
for name in test:
if "_" not in name:
print(name)
|
cs |
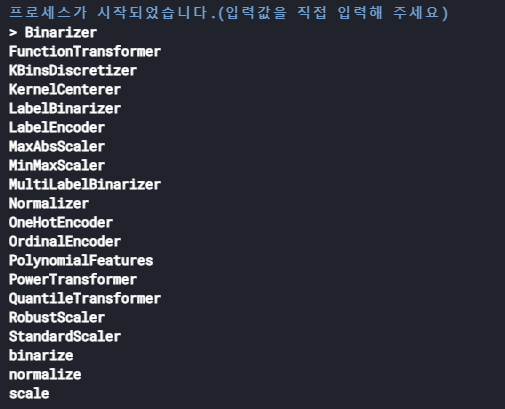
원래는 이 아래의 Module별 자주 사용하는 패키지들을 외우려했는데... 그 수고를 덜 수 있을 것 같습니다.
간단하게 linear_model, svm 이런 식으로만 외어서 가면 될 것 같습니다..!
| cluster | DBSCAN KMeans |
| ensemble | AdaBoostClassifier AdaBoostRegressor BaggingClassifier BaggingRegressor GradientBoostingClassifier GradientBoostingRegressor RandomForestClassifier RandomForestRegressor VotingClassfier VotingRegressor |
| linear_model | LogisticRegression RidgeClassifier LinearRegression Ridege ElasticNet Lasso |
| neighbors | KNeighborsClassifier KNeighborsRegressor |
| neural_network | MLPClassifier MLPRegressor |
| svm | LinearSVC LinearSVR SVC SVR |
| tree | DecisionTreeClassifier DecisionTreeRegressor |
사용하려는 패키지의 설명이 필요한 경우 help( )
이렇게 사용할 패키지를 찾은 다음에 무엇을 입력해야되는지 헷갈리거나! 예제가 필요할 때는 지난 글에서 포스팅했던 help()를 사용하면 되겠지요!
그럼 이런식으로 description부터 필요한 attirbute, 예제와 밑에 추가 함수들까지 나오기 때문에, 구글링하는 것과 비슷한 효과를 가질 수 있을 것 같습니다. (비록 가독성은 떨어지지만요...)
|
1
2
|
from sklearn.preprocessing import MinMaxScaler
help(MinMaxScaler)
|
cs |




또 도움될만한 함수!
df.value_count( ) : Column의 값마다 몇개의 데이터가 있는지 보여줌.
(무슨 데이터 있는지도 볼 수 있네. df.unique( )안쓰고 이걸로 한번에 퉁칠 수 있을 것 같음)

df.unique( ) : 해당 Series 내의 값들의 종류를 반환.

df.groubby('컬럼').통계량() : 해당 컬럼의 값에 따른 mean/ median/ std 등의 기술통계량을 보여줌.

df.isna( ).sum(): 을 하면 column별 True/False 분포를 확인할 수 있음.

메모장 대체
빅분기 실기 시험은 코드 한 번 돌리는 런타임을 1분으로 제한을 뒀기 때문에 parameter 튜닝을 나눠서 돌린 다음 종합하는 코드를 따로 돌려야 될 것 같습니다. 그런데, 시험볼 때 핸드폰은 당연하고 다른 메모할 수 있는 환경이 없을지도 모르니... 중간 시도들을 어떻게 정리하고 아이디어들을 어디다 메모를 할지 궁리를 해봤습니다.
물론 주석처리를 해서 기록을 해도 되겠지만 그래도 답지인데 거기에 막 쓰는 것은 좀 그럴 것 같다는 생각이 들었습니다 ㅋㅋㅋㅋ 그래서 보니 위에 사용 언어를 바꿔도 기존에 작성한 내용이 날아가지 않더라구요. 그래서 Python을 사용할꺼면 R화면을 메모장으로 사용하면 될 것 같습니다 :-)


*근데 메모장 어플도 사용할 수 있다고 하네요
https://cafe.naver.com/sqlpd/21208
[문의] 빅분기 실기 공지와 환경에 대한 전화 문의 (작업형 임의값 제출 의미 / TXT 메모장 사용 가
대한민국 모임의 시작, 네이버 카페
cafe.naver.com
*MinMaxScaler 패키지를 사용한 풀이 추가
- 이것도 ML 패키지와 마찬가지로, 먼저 패키지를 불러와서 선언한 후 .fit으로 데이터를 학습(?)시킨 후 transform으로 적용시키는 과정을 거쳐야 합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
data = pd.read_csv('data/mtcars.csv')
MMS = MinMaxScaler()
# 문자열 데이터가 들어간 Column을 삭제한 데이터를 입력하면
# 각 column을 모두 scale 적용함.
cut_data = data.iloc[:,1:]
MMS.fit(cut_data)
scaled_data = pd.DataFrame(MMS.transform(cut_data), columns = cut_data.keys())
print((scaled_data['qsec']>0.5).sum())
# 그냥 그 Column만 데리고 올 때는, Series에서 .values로 값만 뺀 다음
# 에러메세지에서 시키는대로 .reshape(-1,1)을 해주면 됨
ttt= MMS.fit(data['qsec'].values.reshape(-1,1))
scaled_data =MMS.transform(data['qsec'].values.reshape(-1,1))
print((scaled_data>0.5).sum())
|
cs |
8~13 Line: 다만, Datafram 전체에 적용할 때는 문자열 column을 삭제한 다음에 사용해야 하고,
15~19 Line: Series(한 column)에 적용할 때는 .reshape(-1,1)을 적용한 후 순서를 밟으면 됩니다.
구글링하다가 빅분기 실기 예제에 대한 개요랑 예제 풀이가 자세히 잘 되어 있어있는 곳을 발견해서 공유드립니다.
https://deepcell.kr/bbs/board.php?bo_table=bigbungi
빅데이터분석기사 1 페이지 | 딥셀:AI Campus
빅데이터 분석기사 시험에 관한 게시판입니다.
deepcell.kr
후 이번 주 일요일인 줄 알고 여유부리고 있었는데.... 시험이 토요일 오전이군요...
내일부터는 단답형과 작업형1번도 조금 준비해야겠습니다.
+ 회귀분석 예제 한개 까지!!
그럼 남은 3일 화이팅입니닷!!
'Hobby > Hobby_4 - Coding' 카테고리의 다른 글
| [자격증] 빅분기 실기 - 5. 현실적인 합격 전략, 단답형과 제1유형 (0) | 2021.06.18 |
|---|---|
| [자격증] 빅분기 실기 - 6. 실습환경 마지막 연습(D-1) (0) | 2021.06.18 |
| [자격증] 빅분기 실기 - 3. 분석과정 정리 및 타이타닉 생존 확률 예제 (2) | 2021.06.15 |
| [자격증] 빅분기 실기 - 2. 다른 사람 풀이 정리 (2) | 2021.06.14 |
| [자격증] 빅분기 실기 - 1. 유형 파악 및 풀이 시도 (1) | 2021.06.13 |




댓글