안녕하세요 와우멍입니다.
오늘은 똥줄이 타니 단답형과 1유형을 어떻게 준비할지.. 한번 빠르게 포스팅하겠습니다.
(정리하다보니 길어지네요. 공부하면서 이 글을 업데이트 하는 것으로 변경입니당)
빅데이터 분석기사 실기 벼락치기 현실적인 점수 목표



목표: 단답형 15점 + 제1유형 20점 + 제2유형 25점 = 60점
제가 워낙 단답형에 약해서...ㅠㅠ 여기서 많이 맞춰놓으면 좋은데 ADsP에서도 객관식으로만 거의 통과했었네요.. 조금은 쓸데없는 암기부분말고 실기 진행하면서 필요한 부분에서 문제가 나오길 바라보겠습니다.
제1유형은 계산해서 print를 찍어 부분점수가 없는 녀석이니... 제발 아는 통계량이 나오길 기도하겠습니다. 여기서 두개만 맞춰보죠!!
제2유형은 제출 코드와 답안 모두 확인하니 기본 점수도 있을거고.. 성능에 따른 평가가 들어가니 답이 나온다면 절반 넘게는 점수를 주지 않을까요? 그리고 필기 복습하다보니 ROC-AUC 평가에서는 아래와 같이 급간이 나눠진다고 되어있던데 왠지 이대로 점수를 차등해서 줄 것 같은 느낌입니다!!

1. 단답형 : 15점 목표
최근에 ADsP 시험을 보고 왔는데.. 거기서도 단답형은 거의 다 패스했습니다...
그래서 왠지 이것도 어려울 것 같다는 생각이 드네요... 일단 그래도 보편적인 내용이나 제가 아는 범위 내에서 몇개정도는 나와주길 바라면서... 4개만 맞추는 것을 목표로 가보려합니다.
큰수의 법칙: n이 클수록 표본평균의 분산은 0에 수렴한다.
중심 극한 정리: n이 커지면 모집단의 분포와 상관없이 표본평균은 정규분포에 근사한다.

1종 오류: 귀무가설이 참인데 이를 기각하는 경우
- 유의수준: 1종 오류를 범할 최대 허용확률
- 신뢰수준: 귀무가설이 참일 때, 이를 참이라고 판단하는 확률 (긍까 맞췄다는 거네)
2종 오류: 귀무가설이 참이 아닌데, 이를 채택하는 경우
- 베타수준: 2종 오류를 범할 최대 허용 확률
- 검정력: 귀무가설이 참이 아닌데 이를 기각할 수 있는 확률 (틀린걸 틀렸다고 하는)
퍼셉트론: XOR 선형분리 문제 발생 -> 다층퍼셉트론으로 해결 (시그모이드 함수 사용), 기울기 소실 발생 -> ReLU 함수 사용으로 해결
활성화 함수 종류: 눈에 익혀두기


정상성: 평균이 일정/ 분산이 시점에 의존하지 않음/ 공분산은 시차에만 의존+시점에는 의존 X
시계열 구성요소: 추세요인 + 계절요인 + 순환요인 + 불규칙요인
결측값 종류: 완전 무작위 결측/ 무작위 결측/ 비무작위 결측
결측값 처리 방법
- 완전분석법: 불완전자료는 모두 무시, 추론의 타당성 문제 발생
- 평균대치법: 관측된 자료의 평균값으로 대치
- 단순확률대치법: 확률값을 부여한 후 대치하는 방법 (핫덱: 동일 데이터의 비슷한 성향을 가진 응답자의 데이터/ 콜드덱: 외부 출처 혹은 비슷한 연구에서 가져옴)
이상값 검출 방법
- ESD (평균으로부터 3표준편차까지의 범위)
- 기하평균 활용법(기하평균으로부터 2.5표준편차)
- 사분위수 활용법(1사분위, 3사분위를 기준으로 사분위간 범위의 1.5배 범위, Q1-1.5(Q3-Q1) < data < Q3+1.5(Q3-Q1) )
이상값 처리 방법
- 삭제: 상, 하단 제거 (Trimming)
- 대체법: 상한/하한값을 결정한 후 이 값으로 대체
- 변환: 극단적인 값이 나왔을 때, 데이터 전체에 log를 씌우는 등으로 분포를 변환시킴.
- 박스플롯 사용
변수선택
- 전진 선택법: 결과에 가장 영향 많이 미치는 변수 순으로 추가해나가는 방법
- 후진 제거법: 모두 포함한 모델을 만든 다음, 영향력 작은 변수부터 하나씩 제거하는 방법
- 임베디드기법(LASSO: L-1 norm 제약/ Ridge: L-2 norm 제약/ ElasticNet: 혼합)
| Supervised | Regression | Linear Logistic Decision tree |
| Classifier | Linear Logistic Decision tree SVM Nearest neighbor |
|
| Un-supervised | Clustering | K-means DBSCAN |
| Ensemble | Adaboosting Bagging(bootstrap하는거) Gradientboosting Random forest (약한 예측기 결합) |
|
| PCA | 많은 변수의 분산 패턴을 간결하게 표현하여 주성분 변수를 원래 변수의 선형 결합으로 추출 |
- Logistic Regression: 반응 변수가 범주형이 ㄴ경우 적용하는 회귀분석 모델
- Decision Tree: 데이터가 가진 속성으로 분할 기준 속성을 판별하고, 트리형태로 모델링하는 모델
- Support Vector Machine: Hyperplane에서 데이터들과의 거리가 가장 먼 것을 선택하여 분리
- Random Forest: 약한 학습기들을 생성 후 선형결합하여 최종 학습기를 생성
- Artificial Neural Network: 인간의 뉴런 구조를 모방하여 만든 모델
ADsP 시험으로 나머지 한번 읽어보겠습니닷.
https://cafe.naver.com/sqlpd/20468
이번 ADsP 복원해 봤습니다.
과목내 문제 순서는 뒤죽 박죽이니 참고하시고, 답은 제가 아는건 적었는데 확실하지 않은건 대세가 뭐다 이런식으로 적어놨어요~ 정확한 답을 아시는 분은 적어주시면 좋을거 같네...
cafe.naver.com
2. 제 1유형 : 20점 목표
Print로 답만 출력하는 문제라고 하면... 이상치 검출/ 혼동행렬에서의 파생 지표/ 다른 정규화/ 모델 평가 이런 것들이 나오지 않을까 싶습니다.
다맞추면 좋겠지만 일단은 2개는 꼭 맞출 수 있게 준비해보겠습니다.
이상치 해결: 일단 outlier는 Boxplot값을 이용하여 판별 후 상한/하한값으로 대체하는 것으로 결정했습니다.
결측치 해결: 완전 무작위 결측/ 무작위 결측/ 비무작위 결측
- 완전분석법: 불완전자료는 모두 무시, 추론의 타당성 문제 발생 - 이건 쓰면 안되겠죠!!
- 평균대치법: 관측된 자료의 평균값으로 대치 - 이게 만만해 보입니다.
- 단순확률대치법: 확률값을 부여한 후 대치하는 방법 (핫덱: 동일 데이터의 비슷한 성향을 가진 응답자의 데이터/ 콜드덱: 외부 출처 혹은 비슷한 연구에서 가져옴) - 이건 단답형으로 생각합시다.
상관계수 계산: 피어슨: df.corr('pearson'), 스피어만(df.corr('spearman)
- 이건 걱정했는데, 그냥 함수 바로 쓰면 됩니닷! (df.corr 함수의 기본값이 피어슨입니다)


SSR (Sum of Square Regression): 회귀식과 평균값의 차이
SSE (Sum of Square Error): 회귀식과 실제값의 차이
SST (Sum of Square Total): SSR+SSE
회귀결정계수 (R2, coefficient of determination): SSR/SST = 1- SSE/SST, model.score( ) 이게 회귀결정계수였네.

MSE (Mean Square Error) = SSE/(n-d.o.f)
MSR (Mean Square Regression) = SSR/1
F-ratio = MSR/MSE
카이제곱통계량


지니계수


엔트로피 지수


연관성 분석 : 데이터 내의 상호관계 혹은 종속관계를 찾아내는 기법
(이거 ADsP 서술형에 나왔었네요 살짝 기억납니닷)
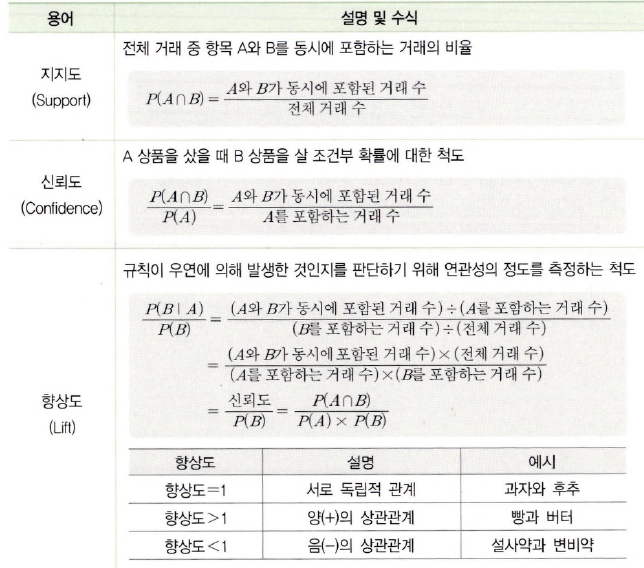
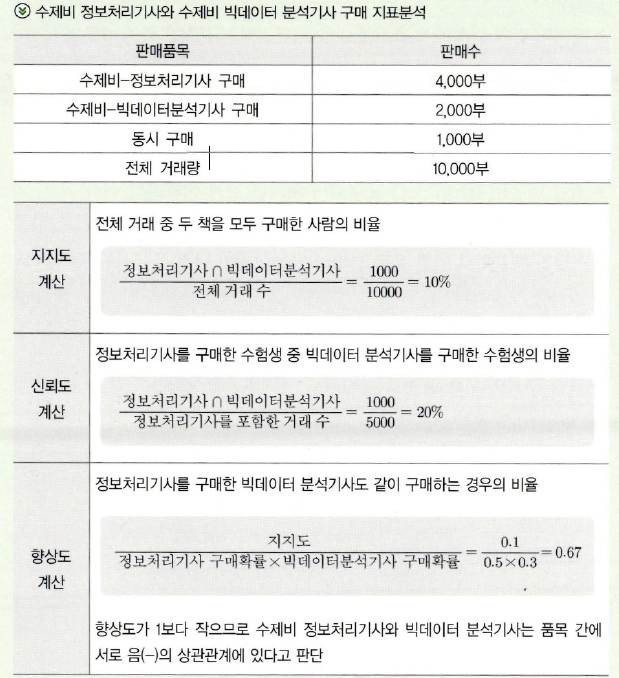
변수거리: 맨해튼 거리 / 유클리드 거리
승산(Odds) = p / (1-p) = 발생할 확률 / 발생하지 않을 확률
승산비 (Odds Ratio) = 관심집단의 승산 / 비교집단의 승산
혼동행렬 개념: 이건 꼭 나오겠죠!!

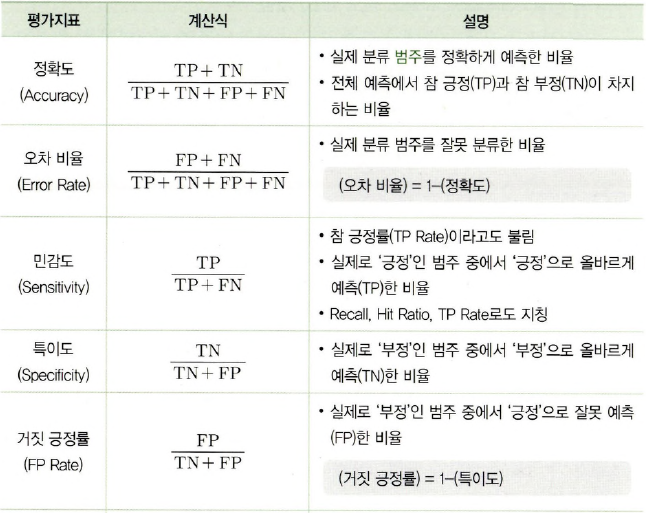

P값 계산:
Z검정/ T검정: https://blog.daum.net/geoscience/1454
파이썬으로 t-검정(T-test) 계산하기
안녕하세요? 이번 글은 파이썬으로 t-검정(T-test)을 계산하는 방법을 정리해 보겠습니다. 이 글은 Towards Data Science(https://towardsdatascience.com/)에서 어뮬리아 앵클(Amulya Aankul) 님이 공유해 주신..
blog.daum.net
다시 읽어보기
https://www.datamanim.com/intro.html
DataManim — DataManim
.md .pdf to have style consistency -->
www.datamanim.com
여기 빅분기 준비하는 분이 차근차근 준비한 사이트도 있는데, 여기도 한 번 참고해보세요!
마지막으로 치달으니까 정리할 시간이 부족하네요 ㅠㅠㅠㅠ
정리하다가 중간에는 거의 속기하듯이 넘어간 것들도 있네요..!!
오늘은 정보 머리에 쑤셔넣는 날이니 눈으로 한번 훑어봅시다.
내일까지 화이팅입니닷.
'Hobby > Hobby_4 - Coding' 카테고리의 다른 글
| [자격증] 빅분기 실기 - 8. 빅분기 합격 후기 (8) | 2021.09.01 |
|---|---|
| [자격증] 빅분기 실기 - 7. 첫 실기시험 후기 (8) | 2021.06.21 |
| [자격증] 빅분기 실기 - 6. 실습환경 마지막 연습(D-1) (0) | 2021.06.18 |
| [자격증] 빅분기 실기 - 4. 빅분기 실기 환경 꿀팁 (0) | 2021.06.16 |
| [자격증] 빅분기 실기 - 3. 분석과정 정리 및 타이타닉 생존 확률 예제 (2) | 2021.06.15 |




댓글