안녕하세요 와우멍입니다.
오늘은 크롤링을 통해 주식 종목별 네이버 검색량을 나타내는 시계열 자료를 만들어보겠습니다.

네이버크롤링을 통한 주식 종목별 검색량 확인
퀀트를 접하고, 백테스팅을 맛보면서 저는 한가지 생각을 했었습니다.
주가를 결정하는 가장 중요한 변수 중 하나는 거래량인데(제가 생각하기에), 거래량은 사람들의 관심과 관련이 있을 것 같고... 그러면 사람들이 많이 검색하는 종목은 주가가 일시적으로 크게 출렁이지 않을까?
그래서 패스트캠퍼스 강의에서 배운 크롤링과 구글링으로 검색한 것들을 토대로, 주가와 검색량의 상관관계를 확인하는 과정을 정리해보았습니다.
셀레니움등을 이용한 동적 크롤링으로 종목을 검색해서 나온 기사의 양을 시간별로 정리해서 하는 방법도 있긴 하겠지만.... 일단은 주어진 툴을 최대한 활용하기 위해 네이버 데이터랩의 검색어트렌드(datalab.naver.com/keyword/trendSearch.naver)를 활용해보겠습니다.
1. 네이버랩 검색어트렌드 구조 확인
우선 이용하려면, 어떤 형태로 이용해야 하는지 확인해봐야겠지요?
검색어트렌드 탭에 들어가서 보면 아래와 같이, 주제어를 정의하고 이와 관련된 연관 검색어를 입력해주는 것을 통해 해당 주제어의 검색트렌드를 확인하는 방식으로 되어 있습니다.
이번에 실습해보면서 보니 2020년 12월 1일 기준으로 코스피/코스닥의 종목수가 2405개인데 이걸 일일이 입력해서 확인해보려면..... 매우매우 힘들고 오래걸리겠지요?

잘 모르니까 일단 데이터랩에서 이 검색어트렌드를 사용해보라고 준 예시를 따라해보면서 감을 잡아봤습니다. 여기에 들어가시면, 저 검색어트렌드를 어떻게 사용하는지 파이썬 예제를 직접 줍니다.
developers.naver.com/docs/datalab/search/#python
통합 검색어 트렌드 API 적용 가이드
통합 검색어 트렌드 API는 '네이버 데이터랩'의 '검색어 트렌드'를 API로 실행할 수 있게하는 RESTful API입니다.
developers.naver.com
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#-*- coding: utf-8 -*-
import os
import sys
import urllib.request
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
url = "https://openapi.naver.com/v1/datalab/search";
body = "{\"startDate\":\"2017-01-01\",\"endDate\":\"2017-04-30\",\"timeUnit\":\"month\",\"keywordGroups\":[{\"groupName\":\"한글\",\"keywords\":[\"한글\",\"korean\"]},{\"groupName\":\"영어\",\"keywords\":[\"영어\",\"english\"]}],\"device\":\"pc\",\"ages\":[\"1\",\"2\"],\"gender\":\"f\"}";
body = {"startDate":"2017-01-01", "endDate":"2018-02-27", "timeUnit":"month", "keywordGroups":[{"groupName":"삼성", "keywords":["삼성","Samsung"]}], "device":"pc","ages":["1","2"]} request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
request.add_header("Content-Type","application/json")
response = urllib.request.urlopen(request, data=body.encode("utf-8"))
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
|
저는 처음에 이거 돌리니까, 저 body 부분이 어떻게 생겨먹은 것인지... 좌우로 너무 길어서 파악이 안되더라구요 ㅠㅠ
깔끔하게 정리하려고 해도 *json 타입의 string가 들어가야 하기 때문에, 중간에 임의로 줄바꿈조차도 에러로 연결되서 저부분을 dictionary로 입력받아 후에 json타입으로 변환해주는 방식으로 수정했습니다.
**json 타입으로 받는 이유는, 자바나 파이썬 등 여러 언어에 걸쳐 사용되어야 하기 때문이라고 합니다.
이 기본 예제를 목적에 맞게, '삼성'이라는 주제어에 대해 '삼성'과 'Samsung'를 연관 검색어로 검색어 트렌드를 할 수 있게 만든 코드는 다음과 같습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
import urllib
from urllib import request
import re
import json
from datetime import datetime
client_id = 'kO0rlKQibESYwzGjrEKc'
client_secret = 'eGEbxpdZbD'
url = "https://openapi.naver.com/v1/datalab/search"
body = {"startDate":"2017-01-01",
"endDate":"2018-02-27",
"timeUnit":"month",
"keywordGroups":[{"groupName":"삼성",
"keywords":["삼성","Samsung"]}],
"device":"pc","ages":["1","2"]}
body = json.dumps(body, )
request = urllib.request.Request(url)# 이건 HTTP Header 변경시에 사용하는 라인, 필요없으면 바로 urllib.request.urlopen()으로 ㄱㄱ
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
request.add_header("Content-Type","application/json")
response = urllib.request.urlopen(request, data=body.encode("utf-8")) # 메서드로 크롤링할 웹페이지 가져옴
rescode = response.getcode() #HTTP 응담 상태 코드
if(rescode==200):
response_body = response.read()
scraped = response_body.decode('utf-8')
else:
print("Error Code:" + rescode)
result = json.loads(scraped)
## result의 'results'에 값이 출력되어 나온다. 그 외의 것은 메타데이터라 보면 될 듯.
data = result['results'][0]['data']
## 이 데이터부분은 start data ~ end data까지 time unit 단위의 숫자만큼의 length를 갖는다
## 이걸 for문을 돌려서 기간별 결과를 확인할 수 있음, 근데 보통 타이틀 하나에 대해서 하는게 효과적인듯?
# time = [datetime.strptime(i['period'], '%Y-%M-%d') for i in data]
time = [pd.to_datetime(i['period']) for i in data]
value = [i['ratio'] for i in data]
data = pd.DataFrame({'Time':time, 'Trend_idx': value})
print(data)
|
cs |
라인별로 무슨 의미를 갖는지는 주석으로 달아놨으니 한번 참고하시면 좋을 것 같습니다.
기본 예제에서 body를 바로 json타입으로 입력했던 것보다, 이렇게 dictionary타입으로 입력하니 어떤 구조인지 더 알아보기 편하지요? (title은 말그래도 우리가 인식할 단어를 이야기하는 거고, 이에 관련검색어들이 뒤에 keywords에 들어가는 것)
검색어트렌드에서 손으로 입력할 때와 마찬가지로, 검색량을 확인할 기간과 기간 단위, 주제어와 연관검색어 그리고 추가옵션으로 성별이나 기기종류(데스크탑인지 모바일인지)도 입력해줄 수가 있네요.
38Line까지에서 조건에 맞는 검색 결과를 리턴하고, 그 뒤에는 이걸 알아보기 편하게 pandas형식으로 변환해줍니다. 이 결과는 다음과 같습니다.
**그런데 43Line에서 주석처리한 것처럼 time을 처리해주면, 연/월/일이 필요한데 숫자가 시/분/초로 분산되면서 이상하게 stamp가 됩니다. 그러니 44Line에서 한 것처럼 pandas의 to_datetime을 사용하는 것을 추천드립니다.
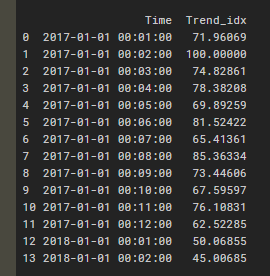

입력한 기간 내에서의 최대값을 기준으로 스케일한 검색량이 반환됩니다. 삼성전자는 17년 2월에 가장 많이 검색되었네요. 무슨일이 있었을까요?
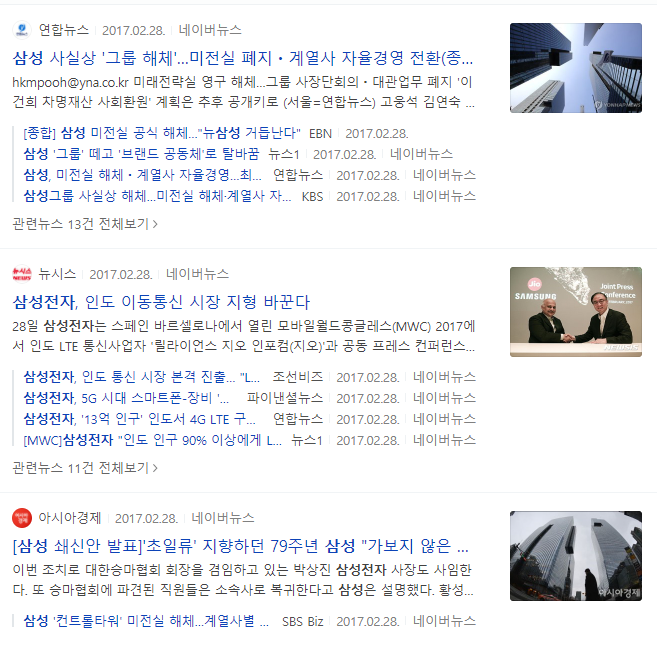
아 이때 국정농단 사건과 연관되어 미전실 해체 등의 풍파를 거치고 있을 때였군요..!! (시간 참 빠르네요;;)
무튼 이런 식으로 이슈가 되어 하방으로 가던, 상방으로 가던 주가의 방향성을 결정하는 지표 역할을 해줄 수 있을 것이라 가정한거였는데, 다음 포스팅에서는 코스피/코스닥의 모든 종목의 검색어 변화 추이를 시계열로 나타내며 이게 주가와 어떤 상관관계를 가질지...!! 가설을 검증해보는 단계를 이야기해보겠습니다.
'Hobby > Hobby_4 - Coding' 카테고리의 다른 글
| [자격증] 빅분기 실기 - 1. 유형 파악 및 풀이 시도 (1) | 2021.06.13 |
|---|---|
| [코딩실전] 주식봇 도전 - 3. 크레온 및 코드 자동실행 (2) | 2021.01.31 |
| [코딩실전] 주식봇 도전 - 2. 변동성돌파 전략 예제 구현 (0) | 2021.01.25 |
| [코딩공부] 필수알고리즘w파이썬 - 2. 스택(Stack)와 큐(Que) (0) | 2021.01.06 |
| [코딩 실전] 주식봇 도전 - 1.파이썬 및 기타 환경 구축 (8) | 2021.01.02 |




댓글