안녕하세요 와우멍입니다.
오늘도 빅데이터 분석기사 실기 벼락치기 과정을 이어서 포스팅하겠습니다.
빅데이터 분석기사 실기 예제 풀이 정리
오늘은 다른 사람들이 풀이한 방법들을 따라해보며 제가 한 것과 어떤 차이가 있는지 공부하면서 정리해보겠습니다. (유튜브 채널 '위대한 개스피'와 '빅공남(빅데이터 공부하는 남자)', '통계파랑'의 영상을 참고했습니다.)

작업형 1. mtcars 데이터셋(mtcars.csv)의 qsec 컬럼을 최소최대 척도(Min-Max Scale)로 변환한 후 0.5보다 큰 값을 가지는 레코드 수를 구하시오.
답변2) sklearn의 Scaler library를 이용하는 방법
scikit learn의 preprocessing module내에 MinMaxScaler 함수가 아예 있습니다.
그래서 이걸 그대로 불러와서, dataset에 적용시키면 됩니다..!
ML module들을 이용할 때와 마찬가지로 Scaler를 선언 후 fit_transform 순으로 적용시켜주면 됩니다.
(다만, fit_transform에서 입력되는 것은 column 하나만 들어가야 해서인지, 5 line에서 선언한 Series를 데리고 fit_transform을 하면 에러가 발생합니다. 그래서 아예 8 line에서와 같이 mtcars을 loc를 통해 slicing하니 결과가 제대로 나왔습니다.)
|
1
2
3
4
5
6
7
8
9
|
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
mtcars = pd.read_csv("data/mtcars.csv")
qsec = mtcars['qsec']
scaler = MinMaxScaler()
minmax =scaler.fit_transform(mtcars.loc[:,['qsec']])
(minmax>0.5).sum()
|
cs |
내 답변 보충) numpy로 넘겨서 함수를 적용하는 것보다는 Pandas dataframe의 기본 함수들을 사용하는 것이 좋을 듯!

- 위 pandas 함수들을 적용하면, 아래와 같이 더욱 간단하게 Min-Max scale을 적용할 수 있다.
|
1
2
3
4
5
6
7
|
import pandas as pd
mtcars = pd.read_csv("data/mtcars.csv")
qsec = mtcars['qsec']
qsec_scale = (qsec - qsec.min()) / (qsec.max()-qsec.min())
output = (qsec_scale > 0.5).sum()
|
cs |
작업형 2. 아래는 백화점 고객의 1년 간 구매 데이터이다. 고객 3500명에 대한 학습용 데이터(y_train.csv, X_train.csv)를 이용하여 성별예측 모형을 마든 후, 이를 평가용 데이터(X_test.csv)에 적용하여 얻은 2482명 고객의 성별 예측값(남자일 확률)을 다음과 같은 형식(custid, gender)의 CSV 파일로 생성하시오. (제출한 모델의 성능은 ROC-AUC 평가지표에 따라 채점)

참고 답변 정리)
1. 전처리 과정
1-1. 명목형 변수와 같은 성별(0/1) 예측이므로, 분류(Classifier)를 위해 준비.
1-2. 단순히 1부터의 숫자를 부여한 'cust_id'를 수치형 변수로 받아들이면, 결과가 왜곡될 수 있으니 지워야 함. 다만, 제출을 위해 cust_id는 미리 만들어 놓자.
1-3. 결측치를 평균/0 등의 값으로 대체, 결측치가 많거나 결과에 영향을 미치지 않을 것이라 판단한다면 그 column 자체를 삭제 등으로 처리.
1-4. 문자형 변수를 숫자형 변수로 변환하기 위해 LabelEncoder를 사용 (LabelEncoder는 문자형 변수들을 0부터 차례대로 숫자를 부여함)
**주의사항: Label Encoding할 때, Train set과 Test set에 들어있는 값이 다를 수도 있으니 binding 후 Label encoding을 한 후 다시 나눠야 제대로 된 labeling이 된다고 할 수 있겠지!!
**x_train[['환불금액','주구매상품']] 이렇게 불러오는 거랑 x_train.loc[:, ['환불금액','주구매상품']] 랑 같음
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.impute import SimpleImputer
# 파일 불러오기
x_train = pd.read_csv('data/X_train.csv')
y_train = pd.read_csv('data/y_train.csv')
x_test = pd.read_csv('data/X_test.csv')
# 결과를 위해 'cust_id' 저장
x_test_id = x_test.loc[:,'cust_id']
# 데이터
x_train = x_train.iloc[:, 1:]
y_train = y_train.iloc[:, -1]
x_test = x_test.iloc[:, 1:]
x_train['환불금액'].fillna(0, inplace=True)
x_test['환불금액'].fillna(0, inplace=True)
x_train.loc[:,['주구매상품', '주구매지점']] = x_train.loc[:,['주구매상품', '주구매지점']].apply(LabelEncoder().fit_transform)
x_test.loc[:,['주구매상품', '주구매지점']] = x_test.loc[:,['주구매상품', '주구매지점']].apply(LabelEncoder().fit_transform)
|
cs |
6~8 line에서 train set과 test set을 불러오고
11 line에서 저장할 결과를 위해 cust_id를 따로 저장하뒀다가
14~16 line에서 1-2의 사항(단순 구분용 숫자의 모델 편입에 따른 예측력 저하 방지)을 위해 'cust_id'를 제거한 다음.
18~19 line에서 '환불금액' column의 결측치들을 0으로 교체
21~22 line에서 명목형 변수들을 숫자형 변수로 encoding
2. 모델 선택 (남/녀 예측이므로 classifier 위주)
2-1. 로지스틱 회귀분석
|
1
2
3
4
5
6
|
## Logistic
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(x_train, y_train)
print('Logistic socre: ',model.score(x_train, y_train))
|
cs |
2-2. K-nearest neighbors
|
1
2
3
4
5
6
|
## KNN
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=4, metric='euclidean')
model.fit(x_train, y_train)
print('KNN socre: ', model.score(x_train, y_train))
|
cs |
2-3. Decision Tree
|
1
2
3
4
5
6
7
|
## Decision Tree
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=1, max_depth=10)
model.fit(x_train, y_train)
print('DTree score: ', model.score(x_train,y_train))
|
cs |
2-4. Support Vector Machine
|
1
2
3
4
5
6
|
## SVM
from sklearn.svm import SVC
model = SVC(C=10, gamma=1, random_state=1, probability=True)
model.fit(x_train, y_train)
print('SVM socre: ', model.score(x_train,y_train))
|
cs |
2-5. Neural Network (Multi-Layer Perceptron Classifier)
|
1
2
3
4
5
6
|
## NN
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(random_state=0, alpha=0.01, hidden_layer_sizes=[50])
model.fit(x_train, y_train)
print('NN score: ', model.score(x_train,y_train))
|
cs |
2-6. Random Forest
|
1
2
3
4
5
6
7
|
## RF
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(max_depth=10, n_estimators=100)
model.fit(x_train, y_train)
print('RF score: ', model.score(x_train,y_train))
|
cs |
위 코드들을 돌린 결과입니다.

지금은 거의 default 값을 이용하여 한 것이긴 하지만, 일단 SVM이 가장 파워풀한 결과를 보여주는 것을 확인할 수 있습니다. 하지만, 이게 over-fitting된 것인지 여부는 확인할 수 없으니... 차후에 다른 문제를 준비하여 hyper parameter 튜닝, Feature Engineering 등을 해보면서 연습을 해볼 필요가 있을 것 같습니다..!!!
3. 결과 가공 및 저장 과정
3-1. concat를 이용해서 병합하기
|
1
2
3
4
|
predict = model.predict_proba(x_test)
predict = pd.DataFrame(predict)
predict = predict.iloc[:,1]
output = pd.concat([x_test_id, predict], axis=1)
|
cs |
pd.concat를 할때 입력되는 녀석들 모두 DataFrame이여야 한다. numpy array를 합치려고 하면 오류남.
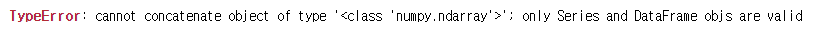
3-2. DataFrame 자체 기능으로 합치기
|
1
2
|
predict = model.predict_proba(x_test)
output = pd.DataFrame({'cust_id':x_test_id, 'gender':predict[:,0]})
|
cs |
3-3. 저장하기
|
1
|
output.to_csv('1234.csv', index=False)
|
cs |
과정을 요약하면 매우 간단합니다..!
1. 데이터 전처리
2. 모델 선정 및 튜닝
3. 다듬고 저장
그럼 다음에는 이 예제에서 사용했던 library들을 포함하여 문제 유형별 필요한 model들을 정리한 다음에 실제 scikit learn에서 어떤 hyper-parameter들을 갖고 있는지를 정리해보겠습니다..!!
그리고 Feature Engineering와 hyper parameter 튜닝 과정도 같이 다뤄야겠습니다.
남은 5일 화이팅입니닷!!
'Hobby > Hobby_4 - Coding' 카테고리의 다른 글
| [자격증] 빅분기 실기 - 4. 빅분기 실기 환경 꿀팁 (0) | 2021.06.16 |
|---|---|
| [자격증] 빅분기 실기 - 3. 분석과정 정리 및 타이타닉 생존 확률 예제 (2) | 2021.06.15 |
| [자격증] 빅분기 실기 - 1. 유형 파악 및 풀이 시도 (1) | 2021.06.13 |
| [코딩실전] 주식봇 도전 - 3. 크레온 및 코드 자동실행 (2) | 2021.01.31 |
| [코딩 실습] 네이버 크롤링을 통한 주식 종목별 검색량 확인하기 - 1 (2) | 2021.01.27 |




댓글